

神经网络优化器
本博客介绍了神经网络训练过程中的常见优化策略,并进行了分析和对比,包括梯度下降、小批量梯度下降、动量梯度下降、RMSProp、Adam 等。下面贴出的代码地址能帮助读者更详细地理解各优化器的实现过程,原理和功能。
代码地址: https://github.com/SkalskiP/ILearnDeepLearning.py
神经网络陷阱:
(1)局部极小值:优化器极易陷入局部极小值从而无法找到全局最优解。
(2)鞍点:当成本函数值几乎不再变化时,就会形成平原(plateau)。在这些点上,任何方向的梯度都几乎为零,使得函数无法逃离该区域。
梯度下降
公式如下:
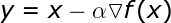
超参数 α 表示学习率,代表算法每次迭代过程的前进步长。学习率的选择一定程度上代表了学习速度与结果准确率之间的权衡。选择步长过小不利于算法求解,且增加迭代次数。反之,选择步长过大则很难发现最小值。此外,该算法很容易受鞍点问题的影响。因为后续迭代过程的步长与计算得到的梯度成比例,所以我们无法摆脱 plateau。且每次迭代过程都要用到整个数据集,不适用于大样本网络。
解决方法:小批量梯度下降,即将完整数据集切分成许多小批量以完成后续训练。
动量梯度下降
动量梯度下降利用指数加权平均,来避免成本函数的梯度趋近于零的问题。简单说,允许算法获得动量,这样即使局部梯度为零,算法基于先前的计算值仍可以继续前进。所以,动量梯度下降几乎始终优于纯梯度下降。
然而,动量梯度下降的不足之处在于,每当临近最小点,动量就会增加。如果动量增加过大,算法将无法停在正确位置。
RMSProp
RMSProp(Root Mean Squared Propagation)是另一种改善梯度下降性能的策略,是最常用的优化器。该算法也使用指数加权平均。而且,它具备自适应性──其允许单独调整模型各参数的学习率。后续参数值基于为特定参数计算的之前梯度值。
其公式如下:

顾名思义,每次迭代我们都要计算特定参数的成本函数的导数平方。此外,使用指数加权平均对近期迭代获取值求平均。最终,在更新网络参数之前,相应的梯度除以平方和的平方根。这表示梯度越大,参数学习率下降越快;梯度越小,参数学习率下降越慢。该算法用这种方式减少振荡,避免支配信号而产生的噪声。为了避免遇到零数相除的情况(数值稳定性),我们给分母添加了极小值 ?。
该优化器的缺点是:由于每次迭代过程中公式的分母都会变大,学习率会逐渐变小,最终可能会使模型完全停止。
Adam
Adam应用广泛且表现不俗,其利用了 RMSProp 的最大优点,且与动量优化思想相结合,形成快速高效的优化策略。然而,随着优化方法有效性的提高,计算复杂度也会增加。


